DeepSeek: Cú sốc mới của Trung Quốc dành cho Thung lũng Silicon
Mã nguồn mở, chi phí thấp kèm hướng dẫn chi tiết cách xây dựng, DeepSeek-R1 là cú sốc mới nhất của Trung Quốc dành cho Thung lũng Silicon.
"Mô hình AI mã nguồn mở, giá rẻ của DeepSeek từ Trung Quốc khiến giới khoa học phấn khích", tờ Nature bình luận sau sự kiện mô hình ngôn ngữ lớn DeepSeek-R1 ra mắt cách đây vài ngày.
Theo tạp chí khoa học uy tín này, hiệu suất của R1 với một số nhiệm vụ nhất định trong hóa học, toán học và mã hóa ngang bằng với mô hình o1 của OpenAI.
Trong khi đó, báo cáo New York Times viết: "Công ty (DeepSeek) đã xây dựng một chatbot rẻ hơn, cạnh tranh hơn, với ít chip máy tính cao cấp hơn so với các gã khổng lồ của Mỹ như Google và OpenAI, qua đó cho thấy hạn chế của việc kiểm soát xuất khẩu chip".
Vậy, R1 là gì và DeepSeek - công ty đứng sau nó là ai? Vì sao mô hình này là cú sốc mới của Trung Quốc dành cho Thung lũng Silicon và rộng hơn là với giới công nghệ toàn cầu?

Một startup AI không theo khuôn mẫu
R1 là một mô hình lý luận AI được thiết kế cho các nhiệm vụ yêu cầu suy luận phức tạp, giải quyết vấn đề toán học và hỗ trợ lập trình. Mô hình này là sản phẩm của DeepSeek - startup được thành lập bởi nhà quản lý quỹ đầu cơ Liang Wenfeng. Ngay cả trong ngành AI của Trung Quốc, DeepSeek cũng là một công ty không theo khuôn mẫu.
Tiền thân của nơi này là Fire-Flyer, một nhánh nghiên cứu học sâu của High-Flyer - một trong các quỹ đầu cơ định lượng có hiệu suất hoạt động tốt nhất Trung Quốc. Thành lập năm 2015, High-Flyer nhanh chóng nổi tiếng và trở thành quỹ đầu cơ định lượng đầu tiên huy động được hơn 100 tỷ CNY (khoảng 15 tỷ USD). Trong nhiều năm, High-Flyer đã tích trữ GPU và xây dựng siêu máy tính Fire-Flyer để phân tích dữ liệu tài chính.
Đến năm 2023, Liang - người có bằng thạc sĩ khoa học máy tính, quyết định đổ nguồn lực của quỹ vào một công ty mới có tên DeepSeek - nơi sẽ xây dựng các mô hình riêng và hy vọng phát triển AI tạo sinh với mục tiêu đạt trình độ ngang con người. Theo Liang, quyết định này được thúc đẩy bởi sự tò mò về khoa học hơn là muốn kiếm lời.
Tôi sẽ không thể tìm ra lý do thương mại (để thành lập DeepSeek) ngay cả khi bạn yêu cầu tôi làm vậy. Bởi nó không đáng để đầu tư về mặt thương mại. Nghiên cứu khoa học về cơ bản có tỷ lệ hoàn vốn đầu tư rất thấp. Khi các nhà đầu tư ban đầu của OpenAI rót tiền cho công ty, họ chắc chắn không nghĩ đến việc sẽ nhận được bao nhiêu lợi nhuận. Thay vào đó, họ thực sự muốn làm điều này.
Liang Wenfeng - Nhà sáng lập DeepSeek
Dù vậy, cùng với ByteDance, DeepSeek vẫn được biết đến với mức thu nhập cao nhất dành cho kỹ sư AI tại Trung Quốc, nhờ số tiền thu được từ giao dịch của quỹ đầu cơ. Đồng thời, startup này là một trong số ít công ty AI hàng đầu đất nước tỷ dân không phụ thuộc vào nguồn tài trợ từ các gã khổng lồ công nghệ như Baidu, Alibaba hay ByteDance.
Theo giới phân tích, nguồn lực tài chính ổn định cùng với tầm nhìn táo bạo và sự tập trung vào hoạt động nghiên cứu khiến DeepSeek trở thành đối thủ nguy hiểm trong lĩnh vực AI. Bởi vì startup này sẽ sẵn sàng chia sẻ các đột phá của mình thay vì bảo vệ chúng để đạt lợi nhuận thương mại. Và trên thực tế, việc này đã diễn ra vào tuần trước khi công ty không chỉ phát hành R1 mà còn cả hướng dẫn chi tiết cho mô hình tiên tiến của mình.
Cú sốc mới dành cho Thung lũng Silicon
Ngay sau khi R1 ra mắt, nhiều cuộc tranh luận sôi nổi đã diễn ra tại Thung lũng Silicon, về việc liệu các công ty AI của Mỹ với nguồn lực tốt hơn, gồm Meta và Anthropic, có thể bảo vệ được lợi thế kỹ thuật của mình trước các đối thủ khác hay không.
Bày tỏ lo ngại về tác động của DeepSeek với sự thống trị của Mỹ trong lĩnh vực AI, CNBC viết: "Một phòng thí nghiệm AI ít được biết tới ở Trung Quốc đã gây ra sự hoảng loạn khắp Thung lũng Silicon sau khi phát hành các mô hình có thể vượt trội hơn so với các mô hình tốt nhất của Mỹ, dù được xây dựng với chi phí thấp hơn và chip yếu hơn".
Cần biết rằng, các công ty Mỹ gồm OpenAI hay Google DeepMind trước đó đã tiên phong trong việc phát triển mô hình lý luận và đang nỗ lực để tạo ra các mô hình có khả năng tư duy tiệm cận trí tuệ con người. Tháng 12 năm ngoái, OpenAI đã phát hành phiên bản đầy đủ của mô hình o1 nhưng vẫn giữ bí mật các phương pháp của mình.
Nên, việc DeepSeek phát hành R1 với mã nguồn mở và chi phí đầu tư cùng nguồn lực bỏ ra thấp hơn nhiều là một cú sốc với Thung lũng Silicon. Ấy là chưa kể đến việc R1 thậm chí sở hữu hiệu suất vượt trội hơn OpenAI o1 trong các lĩnh vực quan trọng.
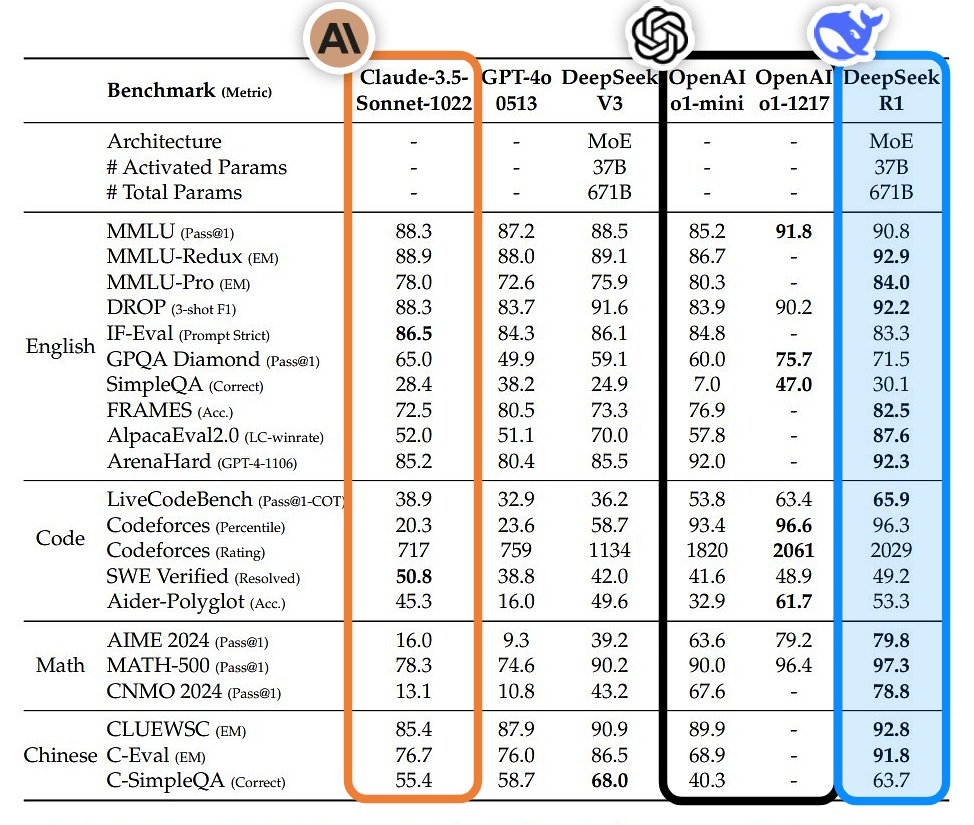
Đặc biệt, DeepSeek tuyên bố sử dụng 2.048 GPU Nvidia H800 và 5,6 triệu USD để đào tạo một mô hình với 671 tỷ tham số, chỉ bằng một phần nhỏ so với số tiền mà OpenAI và Google đã chi để đào tạo các mô hình có quy mô tương đương.
Startup cũng đạt tiến bộ đáng kể về Multi-head Latent Attention (MLA) và Mixture-of-Experts - hai thiết kế kỹ thuật giúp các mô hình DeepSeek tiết kiệm chi phí hơn khi yêu cầu ít tài nguyên tính toán hơn để đào tạo. Thực tế, mô hình mới nhất của DeepSeek hiệu quả đến mức chỉ cần một phần mười sức mạnh tính toán của mô hình Llama 3.1 tương đương của Meta để đào tạo, theo viện nghiên cứu Epoch AI.
DeepSeek đã chứng minh được rằng các mô hình tiên tiến có thể được xây dựng bằng ít tiền hơn, dù con số vẫn rất nhiều, và các chuẩn mực hiện tại về xây dựng mô hình để lại nhiều không gian cho việc tối ưu hóa. Chúng tôi chắc chắn sẽ thấy nhiều nỗ lực hơn nữa theo hướng này trong tương lai.
Wendy Chang - Nhà phân tích chính sách tại Viện nghiên cứu Trung Quốc Mercator
Hạn chế: Chất xúc tác của đổi mới
Thực tế, kể từ giữa năm ngoái, các công ty công nghệ Trung Quốc như Alibaba, Tencent, ByteDance, Moonshot và 01.ai đã liên tục thu hẹp khoảng cách với các công ty cùng ngành tại Mỹ: ngang bằng về năng lực và vượt trội hơn về hiệu quả chi phí. Thành tựu về hiệu quả của Trung Quốc không phải ngẫu nhiên mà là phản ứng trực tiếp với các hạn chế xuất khẩu ngày càng leo thang do Mỹ và các đồng minh áp đặt.
Sau khi Washington cấm Nvidia xuất khẩu các con chip mạnh nhất của mình sang Trung Quốc, các công ty AI địa phương bị buộc phải tìm ra cách tối đa hóa sức mạnh tính toán từ số lượng chip hạn chế mà mình có thể sở hữu. Nói cách khác, sự hạn chế tiếp cận chip của Mỹ đã vô tình thúc đẩy sự đổi mới của các công ty Trung Quốc mà DeepSeek là một trong số đó.
"Họ đã tối ưu hóa kiến trúc mô hình bằng cách sử dụng một loạt thủ thuật kỹ thuật: các lược đồ giao tiếp tùy chỉnh giữa các chip, giảm kích thước của các trường để tiết kiệm bộ nhớ và sử dụng sáng tạo phương pháp kết hợp các mô hình. Nhiều phương pháp trong số này không phải ý tưởng mới, nhưng việc kết hợp chúng thành công để tạo ra mô hình tiên tiến là kỳ tích đáng chú ý", Wendy Chang nói.
Tuy nhiên, không phải ai cũng đồng ý với quan điểm rằng hạn chế của Mỹ góp phần thúc đẩy đổi mới. Theo Gregory Allen - Giám đốc Trung tâm AI Wadhwani tại Trung tâm Nghiên cứu chiến lược và quốc tế, Trung Quốc sẽ tiến bộ bất chấp hạn chế của Mỹ, khi Bắc Kinh từ lâu đã muốn biến đất nước thành siêu cường AI.
Trong khi Mỹ thường thống trị trong hoạt động nghiên cứu mang tính đột phá, các công ty Trung Quốc lại xuất sắc về khả năng thực hiện, chi trả và phổ biến sản phẩm. Trong thương mại điện tử, xe điện, pin mặt trời và pin, họ đã chứng minh được khả năng mở rộng quy mô ấn tượng.
Do đó, với chính quyền mới của Tổng thống Trump, sự trỗi dậy của DeepSeek vừa là lời nhắc nhở sống động, vừa đặt ra một câu hỏi khó chịu: liệu các lệnh trừng phạt ngày càng khắt khe dành cho Trung Quốc có đẩy nhanh chính sự tiến bộ mà chúng được thiết kế để ngăn chặn hay không?